因为Pdg是专用格式,想打开它必须要用专用阅读器才行。所以不少朋友想将PDG文档转换为TIFF、JPG和PNG格式的图像文件,但是不知道使用什么软件。为此分享免费的PDG文件转换工具,它就是Pdg2Pic,将PDG文件转换为图片或PDF文件。
界面预览图:
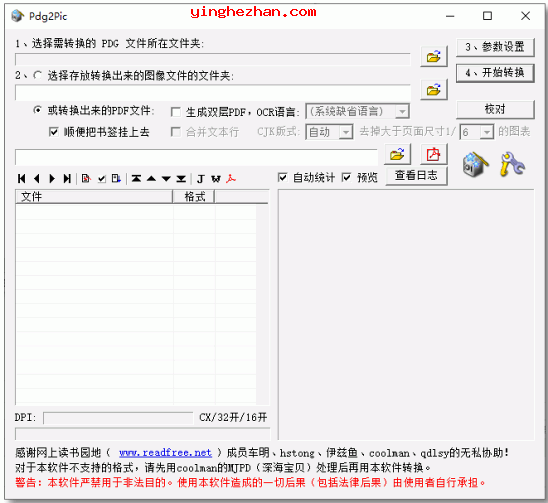
Pdg2Pic是一个用来将PDG文件转成图像文件(包含TIFF、JPG、PNG)或PDF的免费软件。
使用Pdg2Pic您可以方便很多的将是超星的PDG文件转换成为TIFF、JPG与PNG格式的图像文件,或转换成为按封面、前言、目录、正文与附录顺序排列的PDF文件。
该PDG文件转换工具最大的特色在于其预览功能,让你在转换前可以详细了解PDG文件。同时,就算在转换过程中出现错误,软件也会自动记录错误日志,帮你下次免除重复失误。
Pdg2Pic(PDG文件转换工具)功能特点:
1、软件单独运行,不需要SSREADER或其他软件、控件的支持。
2、除彩色版DjVu文件(一般是快速版PDG)外,所有转换均为无损转换。
3、如果转换过程中出现错误,将给出错误日志,便于定位有问题的PDG文件。
4、超星JPG版PDG经常有错,超星浏览器在打开这些数据错误的PDG文件时可能会中断退出,所以提供JPG文件修复功能,对文件进行修复。
5、可以单独对PDF文件设置分段页码,方便根据目录页中的页码直接跳转。
6、支持V1版PDG,及V2版0xH、1xH、28H、AxH,不支持FFH、6xH;支持名为PDG,实为JPG、JPEG 2000、PNG、BMP、GIF、TIFF、DjVu、PDF的文件,但文件名必须符合PDG命名规范。
7、对图像版PDG,可以转换成图像,也可以直接转换成PDF,包含OCR成双层PDF,并提供对自身所生成的双层PDF进行校对所需的辅助功能。
8、对文字版PDG,可以转换成散页PDF,并与图像版附属页统一编号,便于合并。
9、转换成PDF时,支持分段页码、多级目录(书签),可以将目录、BookInfo.dat作为文本添加到PDF文件中,并用BookInfo.dat中的内容填写PDF的Document Properties,包含Title、Author、Subject、Keyword。
使用Pdg2Pic(PDG文件转换工具)将PDG文件转换成为图片教程:

1、选择需要转换的PDG文件所在文件夹。
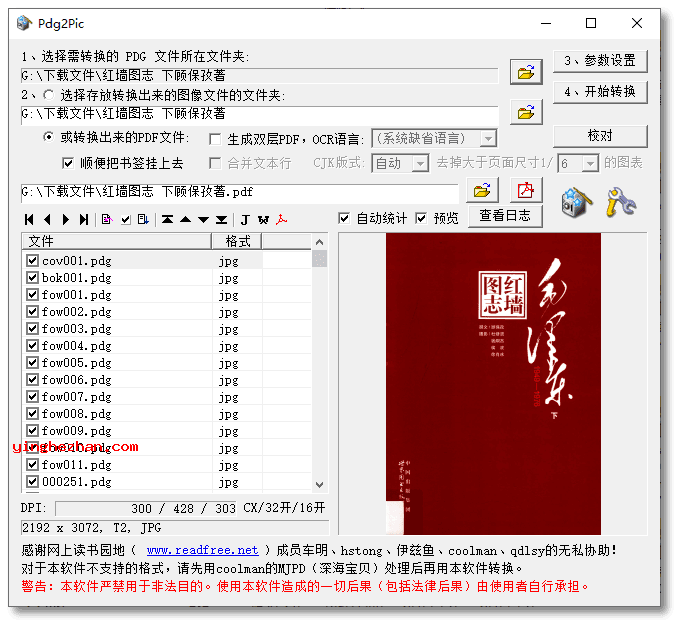
选择后,目录中的所有PDG文件将自动根据封面、前言、目录、正文、附录的顺序排列,并且自动统计、报告PDG文件格式。如果需要对页面顺序进行手工调整,可以用工具条上的按钮改变文件在列表中的位置。如果预览选项被选中(缺省为选中),则在列表右侧的预览窗口会显示当前选中的PDG文件,并在列表下方的信息窗口显示出PDG文件简要信息,包含宽度、高度、DPI、类型 、原始数据格式。类型平常显示为T1(黑白图像)、T2(灰度/彩色图像)、T3(多层图像)。原始数据格式包含CCITT_v1(V1版黑白PDG)、CCITT、JPG与DjVu,T3文件报告底层与第一个插图的格式,中间用+连接。
如果发现显示异常或不能显示的PDG图像,请先在列表中把文件前面的勾号点掉,再进行转换。
如果嫌选择麻烦,或只想转换目录中的几个文件,也可以从资源管理器直接拖拽文件夹或文件到界面上。如果拖过来的是文件夹,则将该目录下所有PDG文件加入列表;如果拖过来的是文件,则将这些文件加入列表。
如果预览选项选项被选中(缺省为选中),则每次选中列表中的文件,均会在预览窗口显示该文件的略缩图。
如果自动统计选项选项被选中(缺省为选中),则每次改变文件或文件夹,均统计并报告列表中的文件格式;不然不统计。
2、选择存放转换出来的图像文件的文件夹,或转换出来的PDF文件。
如果参数设置中选择了目标文件夹与源文件夹相同(缺省为选择),则可忽略这一步:每次在第一步中选择PDG文件夹,均会自动设置图像文件夹 、PDF文件。不然需要点击按钮选择。
转换成PDF的参数选择:
顺便把书签挂上去:选中则生成的PDF带书签,不然不带。对书签的进一步控制可在参数选择中设置。
生成双层PDF:选中则调用MODI进行OCR,生成带隐藏文字的、可检索的双层PDF。因为OCR过程较长,并且MODI的安装也不是所有电脑白痴都能很容易搞定的,所以此选项缺省未选中。
OCR语言:只有在选中生成双层PDF后才有效。OCR语言的选择不仅影响OCR结果的精准度(如明明是繁体字图像,却选择按简体识别),并且影响PDF中的文字编码,所以应尽量精准。
合并文本行:只有在选中生成双层PDF后才有效,如果选中,则将识别结果根据行(横排)或列(竖排)进行合并,不然不合并。合并后的PDF文件长度相对会小一点,校对也方便,但是有时候合并可能会把跨区域的行合并在一起,单个字符的位置可能也会出现变化。
3、设置转换参数。
转换结束后删除原始PDG文件:含义同字面含义。
目标文件夹与源文件夹相同:含义见上面说明。
重新编号转换出来的图像文件:如果选中,则转换出来的文件将按表格中的顺序重新编号,便于用ComicsViewer等图像浏览软件顺序观看,或用图像转PDF软件进行转换;不然转换出来的图像文件与PDG文件的主文件名相同,扩展名不同。
cov002放最后:理论上说PDG的封底页是bac001.pdg,但是不知道为什么,基本上所有PDG书籍的封底都与封面混在一起,所以经常被命名为cov002.pdg。如果该选项未被选中,则cov002就紧接在cov001后面,不然在满足以下条件时,cov002将被放到尾部,起到封底的作用:
重新编号转换出来的图像文件选项被选中。
有cov001、cov002,但没有cov003。
没有bac001。
自动检测灰度图像:对于T2图像,可能是灰度,也可能是彩色。将灰度图像识别出来并保存为灰度JPG,将比保存为彩色JPG更省地方。不过由于检测需要消耗时间,所以此选项缺省为未选中。
JPEG质量系数:对于DjVu图像,可以存为JPG文件,或运用JPG压缩算法的TIFF。该参数控制图像质量的文件大小:此值越大,图像质量损失越小,但是文件长度越大。 就算质量系数为百分之百,也不是无损压缩。
JP2压缩比:即JPEG 2000的压缩率,范围1~100,可控制生成的JP2文件的大小:
最后JP2文件字节数 ≈ 图像像素宽度X图像像素高度XJP2压缩率÷100
当然天下没有白吃的午餐,文件越小,质量越差。就算压缩率为百分之百,也不是无损压缩。
黑白图像存为:TIFF、PNG、BMP。TIFF压缩比大,PNG、BMP兼容性好。均为无损压缩。
彩色/灰度图像存为:JPEG、JPEG TIFF(运用JEPG压缩算法的TIFF)均为有损压缩,PNG为无损压缩,JPEG 2000在JPEG质量系数为百分之百时为无损压缩,其它值时为有损压缩。
此参数只对两种PDG文件有用:
1、DjVu直接更名成PDG,并且是彩色/灰度DjVu。
2、T3类型的多层PDG,会把各层合并成一个单一文件并根据此选项存储,见上面FAQ部分。
很多人挖空心思来回折腾这几个参数,孜孜不倦地追求所谓无损,其实以其半瓶醋晃来晃去,不如直接用缺省值算了。对于外行来讲,有一个简单的办法检验转换是否无损:看转换前后的总文件长度是否变化不大,如果不大多半就是无损的,如果变化很大则多半是有损的。
生成FreePic2Pdf接口文件:如果此选项被选中(缺省为选中),在碰到T3多层格式的PDG文件时,除了生成正常的图像外,还会将每一层图像提取出来生成一个文件,扩展名按层顺序命名为000、001、002等,这些层信息会记录在FreePic2Pdf.itf文件中,之后用FreePic2Pdf将图像转换成PDF文件时,它会自动根据层顺序将图像合并到PDF页面。 此外在选中此选项后,还可以再设置下列子项
1、生成页码:在PDF文件中自动生成三段页码:封面、版权页用大写英文字母,目录页用小写罗马字母,正文页用阿拉伯数字。便于快速定位页面。
2、生成书签:根据bookcontents.dat文件,在PDF中生成多级书签。如果指定的源目录下没有bookcontents.dat文件,将自动生成一个缺省的。
3、显示书签。如果选中,生成的PDF打开即显示书签,不然打开后不显示,需要手工选择才可以看到书签。
4、添加BookInfo.dat到PDF文件尾:这个文件是一个文本文件,添加后便于用Acrobat的搜索功能搜索。
5、添加书签到PDF文件尾:如果此选项被选中,书签内容作为文本添加到PDF文件尾部,便于搜索。
6、展开书签:生成的接口文件中Bkmk段ShowAll的值。选中则生成的PDF文件中所有多级书签都是展开的,不然只显示顶级书签,下级书签折叠。
7、无书签文件时用页码生成书签。如果选中,则在无书签文件(bookcontents.dat或catalog.dat)时用页码生成书签,每个书签项对应一页;不然在无 书签文件时不生成书签。
PDF书签:点击书签项后,是否需要对页面进行缩放。
PDF文件初始视图:选择PDF文件被打开时,以什么样的方式显示给用户。
如果想通过OCR生成双层PDF,则还需选择下列选项:
生成双层PDF:如果此选项被选中,则转换过程中启动OCR,生成隐藏文字,不然只转换图像,不论文字。由于需要时间,MODI的安装也不是电脑白痴随随便便就能搞定的,所以此选项缺省未选中,以免麻烦。
在选中生成双层PDF后,下列选项才可以生效:
OCR语言:一次只能选择一种语言,注意所选项必须与所识别的文字相匹配,例如想识别繁体字,就一定要选择繁体中文,不然识别出来的结果多半会很搞笑。
合并文本行:如果选中,则转换出来的PDF文件中的隐藏文本以行为单位,文件长度较小,但是字的位置不一定精准。如果未选,则以字(CJK)或词(非CJK)为单位,字的位置比较精准,文件长度略大。
CJK版式:中、日、韩文字都有横排与竖排之分,本软件在一定程度上可以自动识别,如果对识别结果不满意,可以手工选择是横排还是竖排。此选项对OCR精准性没有影响,仅对隐藏文字运用的字体有影响。
取消大于页面尺寸1/*的图表:MODI引擎在OCR中日韩语言时相当脆弱,经常因为图表的干扰而造成页面OCR结果为空,甚至整个软件出错退出。我已经尽力捕捉可能的错误,但还是不能根除,因为有时甚至会出现堆栈溢出这样匪夷所思的无法恢复错误。就算出现的是可恢复的错误,也多半会产生内存漏洞,所以在OCR前先对图像清理一遍是一个更安全的做法。判断是否是需要清除的图表的标准相当简单粗暴:二值化图像之后找联通域,只要联通域的高度或宽度大于指定的尺寸,就取消该联通域。这里指定的尺寸是页面宽、高的较小值除以指定的比例之后的结果,该结果如果小于40像素则不在该页面执行去除图表操作。如果指定的比例是1,则所有页面都不会执行自动去除图表操作。
4、开始转换
开始将源文件转换成PDF文件。转换过程中点中止按钮可以中断转换过程。
转换过程中如果出现错误,在转换结束后会报告并询问是否查看错误记录。点击界面上的错误日志,可以查看最近的错误日志。
快捷键1、2、3、4,与界面上的1、2、3、4项功能对应。点击窗口右上角的X按钮即可退出程序。
双层PDF完全基于OCR技术,现在的OCR引擎不可能达到百分之百的精准率,如果想对生成的双层PDF进行人工校对,可以点击校对按钮,进入PDF校对工具界面,使用其中提供的显示、隐藏双层PDF中的文本、删除扫描图像等 工具,辅助完成PDF校对过程。平常的校对过程为:
显示PDF中的隐藏文本,可以设置文字显示颜色、底图透明度。
文字显示出来后,就可以用Foxit PDF Editor、Foxit Phantom对文本进行编辑,包含增加、删除、改变位置、改变显示比例等。推荐使用的编辑工具是Foxit Phantom v2.2.4,更高的版本没有意义,更低的版本则不可靠。
编辑完成后,点隐藏文字页签,把编辑过的文字再次隐藏起来。
如果对校对结果很有信心,也不想再被N多的图像占据存储空间,可以用删除图像功能把原始扫描图像干净、彻底地从PDF中删除。注意删除图像是物理删除,即删除掉的图像再也找不回来,所以请慎重使用此功能。


 图形化adb工具包
图形化adb工具包 文件哈希值批量计算器
文件哈希值批量计算器 notepad3
notepad3 重复文件删除工具
重复文件删除工具 pdf转长图工具
pdf转长图工具 文件夹比较与目录比较工具
文件夹比较与目录比较工具 文件自动分拣工具
文件自动分拣工具 超级批量编码转换器
超级批量编码转换器 Pot划词翻译软件
Pot划词翻译软件 电脑划词翻译软件
电脑划词翻译软件 TXT转EPUB、MOBI工具
TXT转EPUB、MOBI工具 截图翻译软件
截图翻译软件 万能电子书格式转换工具
万能电子书格式转换工具